Validity (more specifically, test validity) is whether a test or instrument is actually measuring the thing it’s supposed to. Validity is especially important in fields like psychology that involve the study of constructs (phenomena that cannot be directly measured).
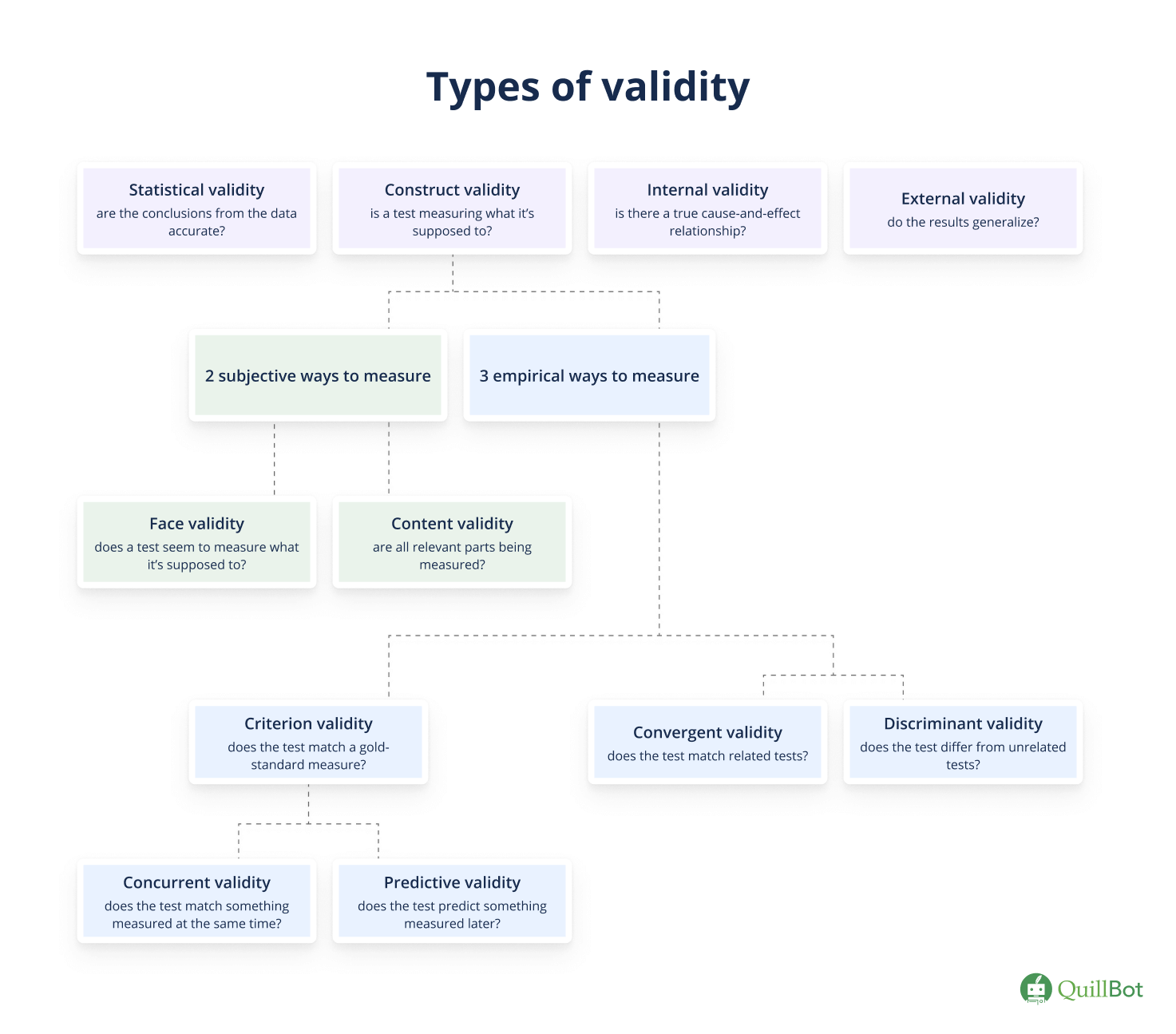
There are various types of test (or measurement) validity that provide evidence of the overall validity of a measure. Different types of validity in research include construct validity, face validity, content validity, criterion validity, convergent validity, and discriminant validity.
Test validity is the primary focus of this article. When conducting research, you might also want to consider experimental validity, which concerns research and experiment design more broadly. Internal validity, external validity, and ecological validity relate to the quality of a study and the applicability of its results to the real world.
TipA generative AI tool, like QuillBot’s AI Chat, can help you analyze potential problems with validity in your own and others’ research. Just be sure to supplement that information with expert opinions and your own judgment.
Discriminant validity (or divergent validity) captures whether a test designed to measure a specific construct yields results different from tests designed to measure theoretically unrelated constructs.
Discriminant validity is evaluated alongside convergent validity, which assesses whether a test produces results similar to tests that measure related constructs. Together, convergent and discriminant validity provide complementary evidence of construct validity—whether a test measures the construct it’s supposed to.
Discriminant validity exampleSuppose you want to study language development in infants. You therefore design a protocol that measures vocabulary recognition.
To ensure that your test is sensitive to this trait and not others, you compare infants’ scores on your test to their scores on a fine motor skills test. You do not expect to observe a relationship between vocabulary recognition and fine motor skills.
A low correlation between infant scores on these tests supports the discriminant validity of your protocol.
Convergent validity is one way to demonstrate the validity of a test—whether it’s measuring the thing it’s supposed to. Specifically, convergent validity evaluates whether a test matches other tests of similar constructs.
If two tests are measuring the same thing, their results should be strongly correlated. This strong correlation indicates convergent validity, which in turn provides evidence of construct validity.
Convergent validity exampleA psychologist wants to create an intake form to quickly evaluate distress tolerance in their patients.
They compare the results of their form to a survey that measures emotional regulation, as they expect this construct to closely relate to distress tolerance.
A high correlation between their form and the existing survey indicates convergent validity.
TipWhen creating any type of survey or questionnaire, accuracy is important. Make sure your questions and answers are clear and error-free with QuillBot’s Grammar Checker.
Construct validity refers to how well a test or instrument measures the theoretical concept it’s supposed to. Demonstrating construct validity is central to establishing the overall validity of a method.
Construct validity tells researchers whether a measurement instrument properly reflects a construct—a phenomenon that cannot be directly measured, such as happiness or stress. Such constructs are common in psychology and other social sciences.
Construct validity exampleA team of researchers would like to measure cell phone addiction in teenagers. They develop a questionnaire that asks teenagers about their phone-related attitudes and behaviors. To gauge whether their questionnaire is actually measuring phone addiction (i.e., whether it has construct validity), they perform the following assessments:
The team evaluates face validity by reading through their questionnaire and asking themselves whether each question seems related to cell phone use.
The team measures criterion validity by comparing participants’ questionnaire results with their average daily screen time. They expect to see a high correlation between these two variables.
Finally, the researchers examine divergent validity by comparing their questionnaire results to those of a standard creativity test. Because the constructs of phone addiction and creativity should theoretically be unrelated, the researchers expect to see a low correlation between these test results.
If the researchers successfully demonstrate the face validity, criterion validity, and divergent validity of their questionnaire, they have provided compelling evidence that their new measure has high construct validity.
Criterion validity (or criterion-related validity) is an assessment of how accurately a test or instrument captures the outcome it was designed to measure. These outcomes are generally constructs that cannot be directly measured, such as intelligence or happiness. Such constructs occur frequently in psychology research.
Criterion validity is determined by comparing your test results to a “gold standard,” or criterion, that acts as a ground truth. If your test and the criterion are measuring the same construct, they should be highly correlated (i.e., have high criterion validity).
There are two types of criterion validity, which differ in their timelines of comparison. Concurrent validity compares two measures administered at the same time, whereas predictive validity captures how one measure correlates with a second measure taken in the future.
Criterion validity exampleA technology company has created a watch that uses biometric data to estimate users’ stress levels. However, they want to ensure that their estimate of stress has criterion validity. This can be done by measuring either concurrent or predictive validity.
Concurrent validity could be assessed by comparing the watch’s real-time estimate of stress levels to a validated measure of stress administered at the same time, such as the Perceived Stress Scale.
Predictive validity could be determined by examining whether initial watch estimates of stress correlate to future health outcomes associated with chronic stress, such as hypertension.
If the watch estimates are highly correlated with the Perceived Stress Scale or future measures of hypertension, the company has successfully established criterion validity.
When researchers want to measure constructs (i.e., abstract concepts) like “happiness” or “job satisfaction,” they rely on instruments like surveys or tests. However, how can they ensure that these tools are accurately measuring what they are intended to? This is where concurrent validity comes in.
Concurrent validity evaluates the accuracy of a new test by comparing it to one that’s already well established. Both tests are measured at the same time—concurrently—and the established measure acts as a gold standard. If both tests yield similar results, the new test has high concurrent validity.
Concurrent validity is a type of criterion validity and is commonly used in psychology, business, healthcare, and education research.
Concurrent validity in psychology exampleImagine you’re a psychology student interested in how anxiety levels relate to exam performance. You need a fast and convenient way to measure anxiety. You’ve therefore developed a short survey to assess the anxiety levels of your classmates.
You could determine the concurrent validity of your new measure by comparing its results to those of the Generalized Anxiety Disorder Scale (GAD-7), a well-established anxiety assessment tool. A sample of students could complete your survey alongside the GAD-7. If the results of both tests are very similar, they will be highly correlated. You can therefore conclude that the concurrent validity of your new survey is high.
TipWhen you’re developing questionnaires and other survey instruments, it is very important they be as clear as possible. Use QuillBot’s free Grammar Checker to eliminate any mistakes.